

Portal Weekly #35: transfer learning for protein language models, improving antibody design, combination drug screens, and more.
Portal Weekly #35: transfer learning for protein language models, improving antibody design, combination drug screens, and more.
Join Portal and stay up to date on research happening at the intersection of tech x bio 🧬



Hi everyone 👋
Welcome to another issue of the Portal newsletter where we provide weekly updates on talks, events, and research in the TechBio space!
💻 Latest Blogs
Last week we had a blog post by Nathan Frey from Prescient Design/Genentech, not just covering his recent Nature Machine Intelligence paper on how well deep chemical models scale, but also editorializing based on his experience within a drug discovery ML research lab. Check it out here!

💬 Upcoming talks
M2D2 continues next week with a presentation by Susana Vazquez Torres from the Baker lab, who will tell us about her recent study focusing on designing proteins that can bind alpha-helices, relevant for detecting peptide hormones and other biomolecules.
Join us live on Zoom on Tuesday, February 20th at 11 am ET. Find more details here.

LoGG continues with a talk by Jesse Lai and Yuki Mitsufuji on a way to trade off speed and sample quality when sampling using score-based diffusion models.
Join us live on Zoom on Monday, February 19th at 11 am ET. Find more details here.

Speakers for CARE talks are usually announced on Fridays after this newsletter goes out. Sign up for Portal and get notifications when a new talk is announced on the CARE events page. You can also follow us on Twitter!
If you enjoy this newsletter, we’d appreciate it if you could forward it to some of your friends! 🙏
Let’s jump right in!👇
📚 Community Reads
LLMs for Science
Leveraging Large Language Models for Predictive Chemistry
LLMs are increasingly frequently being turned towards the sciences, with sometimes surprising results. This study adapted GPT-3, which is trained on a huge amount of text from the internet, to answer chemical questions in natural language. Their results suggest that their fine-tuned GPT-3 can do as well as or better than conventional ML techniques, and can also perform inverse design. This model may be particularly useful in low-data regimes, where it may be able to better leverage collective knowledge.
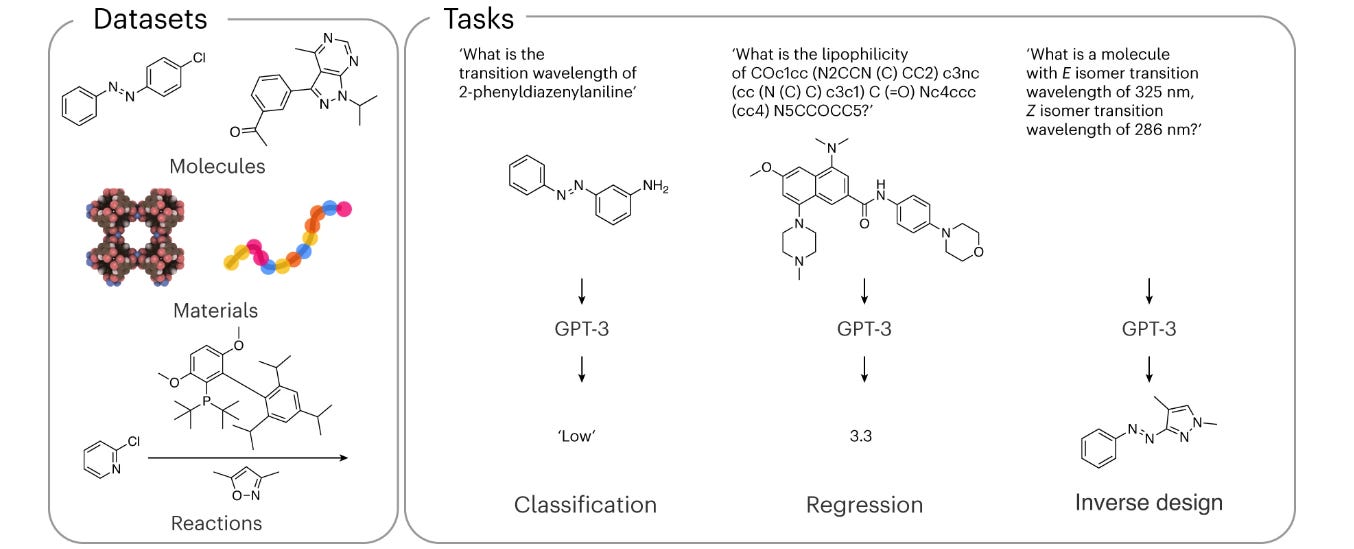
ML for Small Molecules
Augmented Drug Combination Dataset to Improve the Performance of Machine Learning Models Predicting Synergistic Anticancer Effects
Data augmentation has been very successful in computer vision - even rotating images different ways or changing the colour scheme can help a model learn a more robust representation. This study suggests a data augmentation strategy for cases in drug combination therapy where you may not have enough data to build good models. They propose augmenting data by substituting a compound in a drug combination instance with another one that shows similar pharmacological effects. The results indicate that this may help models achieve higher accuracy than if they were trained on an un-augmented dataset.

Graph Learning
MedGAN: Optimized Generative Adversarial Network with Graph Convolutional Networks for Novel Molecule Design
Studies combining a GAN (where two models are trained simultaneously, one to generate molecules and the other to determine whether the molecules come from the training data) and a graph convolutional network (to represent the molecules) have already been done, but they have achieved only small molecular graphs. The authors of this study were interested in whether a more targeted approach could improve the process, selecting a single scaffold with known biological interest and elaborating on it. They chose the quinoline family of molecules, and tested how different hyperparameters and estimations of drug-likeness (ADMET etc.) affected model performance. This kind of study can be useful in understanding how different modeling decisions affect the performance of generative models, allowing us ultimately to make better drugs.

ML for Atomistic Simulations
Enhanced Sampling of Robust Molecular Datasets with Uncertainty-Based Collective Variables
Machine learning interatomic potentials depend on having a dataset that is representative of the accessible configuration space of a molecular system. Because of the complexity of molecular systems, though, it’s hard to generate representative datasets. This study proposes focusing on regions where ML models are most uncertain, using a Gaussian Mixture Model-based metric to guide the inclusion of chemically-relevant datapoints in the dataset. Their results suggest that they are better able to explore unseen energy minima, giving them an enhanced dataset.

ML for Proteins
Feature Reuse and Scaling: Understanding Transfer Learning with Protein Language Models
Ideally, we would train a protein language model and it would learn a robust representation of protein biology that we would then be able to apply to numerous downstream tasks. This study does a systematic investigation of transfer learning, seeing where pretrained models of different sizes, depths, architectures and pretraining times perform well on different tasks. They find that while generally pretraining helps on downstream tasks, performance did not scale with pretraining and the most important features are learned fairly early in pretraining. This suggests a need for better pretraining methods, but also might indicate a path forward.

Addressing the Antibody Germline Bias and its Effect on Language Models for Improved Antibody Design
Antibodies are attractive therapeutics, since they can bind highly specifically to a target and harness the body’s defense mechanisms against it. Antibody-specific language models use databases like the Observed Antibody Space (OAS), which may be biased against the highest-affinity, most specific antibodies (produced by matured B-cells) because of how the samples are collected. Since a model is only as good as its training data, the authors suspected that models trained on the OAS may have less diversity than one might expect. When they trained new models that were optimized for predicting non-germline residues, they saw a greater sequence diversity of generated antibodies. Hopefully, we’ll see experimental validation of greater binding affinity in a subsequent paper!

ML for Omics
TISSUE: Uncertainty-Calibrated Prediction of Single-Cell Spatial Transcriptomics Improves Downstream Analyses
There have been many methods developed to predict spatial gene expression in unmeasured transcripts, but the quality of these predictions varies. This study proposes TISSUE as a general framework to estimate uncertainty and provide prediction intervals for expression values across 11 benchmark datasets. They suggest that their model reduces the false discovery rate for differential gene expression analysis and improves the performance of supervised learning models trained on predicted gene expression profiles.

A Bayesian Active Learning Platform for Scalable Combination Drug Screens
The combinatorial space in biology is too vast to screen through without a plan. We’ve featured ways of iteratively screening before here. This study is interested in how to conduct combination drug screens for cancer treatment. They use information theory and probabilistic modeling to design each batch of experiments to be maximally informative based on the results of previous experiments. Their results suggest that their approach is accurate at detecting synergies and predicting novel combinations after only exploring < 5% of the experimental space. They prospectively validate their top hits on a form of cancer called Ewing sarcomas and find that they are effective, providing good evidence that the approach is useful and can work in the real world.

Open Source
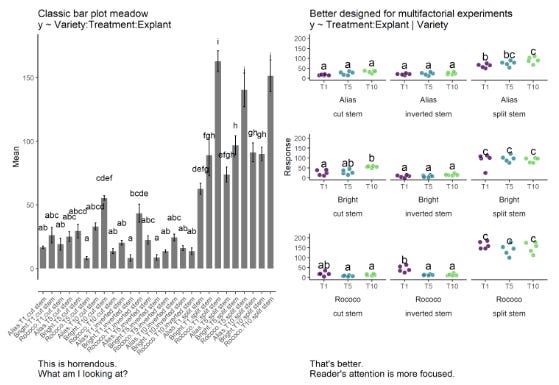
Friends Don't Let Friends Make Bad Graphs
It’s easy to throw a figure into a paper, but graphs can mislead. This “opinionated essay” discusses good and bad practices in data visualization, and should be a mandatory read when starting out in science, if for no other reason than to encourage thinking about what one is trying to convey.
Think we missed something? Join our community to discuss these topics further!
🎬 Latest Recordings
M2D2
Predictive Chemistry Augmented with Text Retrieval by Zhening Li
LoGG
Protein Discovery with Discrete Walk-Jump Sampling by Nathan Frey
You can always catch up on previous recordings on our YouTube channel or the Portal Events page!
Portal is the home of the TechBio community. Join here and stay up to date on the latest research, expand your network, and ask questions. In Portal, you can access everything that the community has to offer in a single location:
M2D2 - a weekly reading group to discuss the latest research in AI for drug discovery
LoGG - a weekly reading group to discuss the latest research in graph learning
CARE - a weekly reading group to discuss the latest research in causality
Blogs - tutorials and blog posts written by and for the community
Discussions - jump into a topic of interest and share new ideas and perspectives
See you at the next issue! 👋